Команда grep (расшифровывается как global regular expression print) – одна из самых востребованных команд в терминале Linux, которая входит в состав проекта GNU. Grep это утилита командной строки Linux, который даёт пользователям возможность вести поиск строки. С его помощью можно даже искать конкретные слова в файле.
Оглавление
Применение grep в Linux
Одна из более полезных и многофункциональных команд в терминале Linux – бригада «grep». Grep – это акроним, какой расшифровывается как «global regular expression print» (то имеется, «искать везде соответствующие постоянному выражению строки и выводить их»).
Это значит, что grep возможно использовать для того, чтобы проглядеть, соответствуют ли вводимые данные заданным шаблонам. В простенькой форме grep используется для розыска совпадений буквенных шаблонов в текстовом файле. Это значивает, что если команда grep приобретает слово для поиска, она будет выводить каждую сохраняющую это слово строку файла.
Назначение grep — поиск строк согласно условию, изображенному регулярным выражением. Существуют изменения классического grep — egrep, fgrep, rgrep. Все они отточены под конкретные цели, при этом способности grep перекрывают весь функционал. Самым несложным примером использования команды представляется вывод строки, удовлетворяющей шаблону, из файла. Пример мы хотим найти строку, сохраняющую ‘user’ в файле /etc/mysql/my.cnf. Для этого воспользуемся последующей командой:
grep user /etc/mysql/my.cnf
Grep сможет просто искать конкретное словечко:
grep Hello ./example.cpp
Или строку, но в таком варианте её нужно заключать в кавычки:
grep ‘Hello world’ ./example.cpp
В добавление альтернативами программы являются egrep и fgrep, которые являются тем же самым, что и, соответственно, grep -E и grep -F. Варианты egrep и fgrep являются устаревшими, но работают для обратной совместимости. Вместо устаревших вариантов рекомендуется использовать grep -E и grep –F.
Команда grep сопоставляет строки исходных файлов с шаблоном, этим базовым регулярным выражением. Если файлы не указаны, используется стандартный ввод. Как как обычно каждая успешно сопоставленная строка копируется на стандартный вывод; если
исходных файлов чуть-чуть, перед найденной строкой выдается имя файла. В качестве шаблонов воспринимаются базовые непрерывные выражения (выражения, имеющие своими значениями цепочки символов, и использующие ограниченный комплекс алфавитно-цифровых и специальных символов).
Использование egrep в Linux
Egrep или grep -E — это другая версия grep или Extended grep. Эта версия grep превосходна и быстра, когда дело доходит до поиска шаблона регулярных выражений, поскольку она обрабатывает метасимволы как есть и не заменяет их как строки. Egrep использует ERE или Extended Extended Expression.
egrep — это урезанный вызов grep c ключом -E Отличие от grep заключается в возможности использовать расширенные непрерывные выражения с использованием символьных классов POSIX. Часто возникает задача поиска словечек или представлений, принадлежащих к одному типу, но с возможными вариациями в написании, такие как даты, фамилии файлов с некоторым расширением и стандартным названием, e-mail адреса. С другой стороны, имеется задачи по пребыванию вполне определенных слов, которые могут иметь различное начертание, либо розыск, исключающий отдельные символы или классы символов.
Для этих целей истины созданы некоторые системы, основанные на описании текста при помощи шаблонов. К таким системам причисляются и постоянные выражения. Два очень полезные спецсимвола — это ^ и $, которые обозначают начало и конец строки. Например, мы хотим получить всех пользователей, зарегистрированных в нашей системе, имя которых начинается на s. Тогда можно применить регулярное выражение «^s». Вы можете использовать бригаду egrep:
egrep “^s” /etc/passwd
Есть возможность поиска по нескольким файлам и в подобном случае перед строкой выводится имя файла.
egrep -i Hello ./example.cpp ./example2.cpp
А следующий запрос выводит весь код, исключая строки, содержащие только комментарии:
egrep -v ^/[/*] ./example.cpp
В виде egrep, даже если вы не избегаете метасимволы, команда будет относиться к ним как к специальным символам и заменять их своим особым значением вместо того, чтобы рассматривать их как часть строки
Использование fgrep в Linux
Fgrep или Fixed grep или grep -F — это еще одна версия grep, какой-никакая необходима, когда дело доходит до поиска всей строки вместо регулярного понятия, поскольку оно не распознает ни регулярные выражения, ни метасимволы. Для поиска любой строки напрямую выбирайте эту версия grep.
Fgrep ищет полную строку и не распознает специальные символы как часть непрерывного выражения, несмотря на то экранированы символы или нет.
fgrep -C 0 ‘(f|g)ile’ check_filefgrep -C 0 ‘(f|g)ile’ check_file
Использование sed в Linux
sed (от англ. Stream EDitor) — потоковый текстовый редактор (а также язычок программирования), использующий различные предопределённые текстовые преобразования к последовательному потоку текстовых этих. Sed можно утилизировать как grep, выводя строки по шаблону базового регулярного выражения:
sed -n /Hello/p ./example.cpp
Может быть использовать его для удаления строк (удаление всех пустых строк):
sed /^$/d ./example.cpp
Основным инструментом работы с sed является выражение типа:
sed s/искомое_выражение/чем_заменить/имя_файла
Так, образчик, если выполнить команду:
sed s/int/long/ ./example.cpp
Выше рассмотрены различия меж «grep», «egrep» и «fgrep». Невзирая на различия в наборе используемых регулярных представлений и скорости выполнения, параметры командной строчки остаются одинаковыми для всех трех версий grep.
Синтаксис для команды grep
- -i: Используется для игнорирования соответствующего регистра.
- -c: выводит количество совпадающих строк.
- -l: отображает список имен файлов.
- -n: количество совпавших строк и номера их строк.
- -v: количество линий, которые не соответствуют шаблону.
- -w: соответствовать всему слову
Как использовать команду Grep?
Принадлежащая к семейству Unix команда grep является одним из самых универсальных и полезных инструментов. Эта утилита выполняет поиск в текстовом файле за заданным нами паттерном. Другими словами, с помощью grep вы можете найти необходимое вам слово или значение. А содержащие ваш запрос строки или строка будут выведены в терминал.
На первый взгляд, может показаться, что эта утилита имеет слишком узкое применение. Однако она способна значительно облегчить жизнь системным администраторам, которым приходится обрабатывать множество служб с различными файлами конфигурации. С помощью команды они могут быстро найти необходимые им строки в этих файлах.
Сначала давайте подключимся к VPS с помощью SSH. Вот статья, в которой показано, как это сделать с помощью PuTTY SSH.
ssh vash-user@vash-server
Если на вашем компьютере вы используете Linux, просто откройте терминал.
Синтаксис команды grep при поиске в одном файле выглядит следующим образом:
grep [опции] значение [ФАЙЛ]
- grep — команда
- [опции] — модификаторы команды
- значение — поисковый запрос
- [ФАЙЛ] — файл, в котором вы выполняете поиск
Вы можете просмотреть документацию и пояснения к различным опциям команды, введя в командной строке:
grep –help
Как видите, команда предлагает нам множество опций. Однако наиболее важными и часто используемыми являются параметры:
- -i — поиск не будет чувствителен к регистру. То есть, если вы хотите найти слово «автомобиль», написанные как «АВТОМОБИЛЬ» слова тоже будут найдены.
- -c — покажет только количество строк, содержащих поисковый запрос
- -r — включает рекурсивный поиск в текущем каталоге
- -n — выведет номера строк, содержащих поисковый запрос
- -v — обратный поиск, выводит только строки, в которых нет указанного поискового запроса
Подготовительные работы
Все дальнейшие действия будут производиться через стандартную консоль, она же позволяет открывать файлы только путем указания полного пути к ним либо если «Терминал» запущен из необходимой директории. Узнать родительскую папку файла и перейти к ней в консоли можно так:
-
- Запустите файловый менеджер и переместитесь в нужную папку.
-
- Нажмите правой кнопкой мыши на требуемом файле и выберите пункт «Свойства».
-
- Во вкладке «Основные» ознакомьтесь со строкой «Родительская папка».
-
- Теперь запустите «Терминал» удобным методом, например, через меню или зажатием комбинации клавиш Ctrl + Alt + T.
-
- Здесь перейдите к директории через команду cd /home/user/folder, где user — имя пользователя, а folder — название папки.
Задействуйте команду cat + название файла, если хотите просмотреть полное содержимое. Детальные инструкции по работе с этой командой ищите в другой нашей статье по ссылке ниже.
Благодаря выполнению приведенных выше действий вы можете использовать grep, находясь в нужной директории, без указания полного пути к файлу.
Стандартный поиск по содержимому
Прежде чем переходить к рассмотрению всех доступных аргументов, важно отметить и обычный поиск по содержимому. Он будет полезен в тех моментах, когда необходимо найти простое совпадение по значению и вывести на экран все подходящие строки.
-
- В командной строке введите grep word testfile, где word — искомая информация, а testfile — название файла. Когда производите поиск, находясь за пределами папки, укажите полный путь по примеру /home/user/folder/filename. После ввода команды нажмите на клавишу Enter.
- Осталось только ознакомиться с доступными вариантами. На экране отобразятся полные строки, а ключевые значения будут выделены красным цветом.
-
- Важно учитывать и регистр букв, поскольку кодировка Linux не оптимизирована для поиска без учета больших или маленьких символов. Если вы хотите обойти определение регистра, впишите grep -i “word” testfile.
-
- Как видите, на следующем скриншоте результат изменился и добавилась еще одна новая строка.
Пример использования
Допустим, требуется быстро найти фразу «our products» в HTML-файлах на компьютере. Начнем с поиска в одном из них. В данном случае ШАБЛОН – это «our products», а ФАЙЛ – product-listing.html
$ grep “our products” product-listing.html
You will find that all of our products are impeccably designed and meet the highest manufacturing standards available anywhere.
$
Была найдена одна строка, содержащая указанный шаблон, и grep выводит всю соответствующую строку на терминал. Строка длиннее ширины окна терминала, поэтому текст переносится на следующие строки, но данный вывод соответствует ровно одной строке в файле.
Важно: ШАБЛОН интерпретируется grep как регулярное выражение. В рассмотренном выше примере все использованные символы (буквы и пробел) интерпретируются в регулярных выражениях буквально, поэтому выполняется только поиск точной фразы. Однако, у других символов, например, некоторых знаков препинания, может быть особое значение.
1. Простой поиск в файле
Давайте рассмотрим пример в файле “/etc/passwd” для поиска строки в файле. Чтобы найти слово “system” при помощи команды grep, используйте команду:
[root@destroyer ~]# cat /etc/passwd|grep systemПример вывода:
systemd-bus-proxy:x:899:897:systemd Bus Proxy:/:/sbin/nologin systemd-network:x:898:896:systemd Network Management:/:/sbin/nologin
2. Подсчет появления слов.
В приведенном выше примере мы имеем в системе поиск слов в файл
е “/etc/passwd”. Если мы хотим знать количество или число появлений слова в файле, то используйте опцию ниже:
[root@destroyer ~]# cat /etc/passwd|grep -c system 2 [root@destroyer ~]#Выше указанно, что слово появилось два раза в файле “/etc/passwd”.
3. Игнорировать регистрозависимые слова
Команда grep чувствительна к регистру, это означает, что он будет искать только данное слово в файле. Чтобы проверить эту функцию, создайте один файл с именем «test.txt» и с содержанием, как показано ниже:
[root@destroyer tmp]# cat test.txt AndreyEx andreyex ANDREYEX Andreyex [root@destroyer tmp]#Теперь, если вы попытаетесь найти строку «andreyex», то команда не будет перечислять все слова «andreyex» с разными вариантами, как показано ниже:
[root@destroyer tmp]# grep andreyex test.txt andreyex [root@destroyer tmp]#Этот результат подтверждает, что только один вариант будет показан, игнорируя остальную часть слова «andreyex» с разными вариантами. И если вы хотите игнорировать этот случай, вам нужно использовать параметр «-i» с grep, как показано ниже:
[root@destroyer tmp]# grep -i andreyex test.txt AndreyEx andreyex ANDREYEX Andreyex4. Две разные строки внутри файла с командой grep
Теперь, если вы хотите найти два слова или строки с помощью команды grep, то вы должны задать расширенные. В следующей команде мы находим две строки «system» и «nobody» в файле /etc/passwd.
[root@destroyer ~]# grep ‘system|nobody’ /etc/passwd nobody:x:89:89:Nobody:/:/sbin/nologin systemd-bus-proxy:x:899:897:systemd Bus Proxy:/:/sbin/nologin systemd-network:x:898:896:systemd Network Management:/:/sbin/nologin [root@destroyer ~]#5. Рекурсивный поиск
Допустим, вы хотите найти слово или строку рекурсивно в любом месте каталога, тогда используйте опцию -r. Например, если вы хотите найти слово «check_oracle» рекурсивно в каталоге /etc, то используйте следующую команду:
[root@destroyer ~]# grep -r “check_oracle” /etc/ /etc/selinux/targeted/contexts/files/file_contexts:/usr/lib/nagios/plugins/check_oracle — system_u:object_r:nagios_services_plugin_exec_t:s0 Binary file /etc/selinux/targeted/contexts/files/file_contexts.bin matches /etc/selinux/targeted/modules/active/file_contexts:/usr/lib/nagios/plugins/check_oracle — system_u:object_r:nagios_services_plugin_exec_t:s0 /etc/selinux/targeted/modules/active/file_contexts.template:/usr/lib/nagios/plugins/check_oracle — system_u:object_r:nagios_services_plugin_exec_t:s0 [root@destroyer ~]В выводе выше мы можем иметь возможность видеть имя файла, в котором мы нашли строку, и если вы хотите убрать имя файла в конечном результате, то используйте опцию «-h», как показано ниже:
[root@destroyer ~]# grep -hr “check_oracle” /etc/ /usr/lib/nagios/plugins/check_oracle — system_u:object_r:nagios_services_plugin_exec_t:s0 Binary file /etc/selinux/targeted/contexts/files/file_contexts.bin matches /usr/lib/nagios/plugins/check_oracle — system_u:object_r:nagios_services_plugin_exec_t:s0 /usr/lib/nagios/plugins/check_oracle — system_u:object_r:nagios_services_plugin_exec_t:s0 [root@destroyer ~]#6. Вывод команды grep.
Если вы хотите найти строку или слово в любом выводе команды, то вы должны использовать оператор «|», а затем <строка> в grep. Допустим, вы хотите найти в памяти, связанные слова вывода команды dmesg, то используйте следующую команду.
[root@destroyer ~]# dmesg |grep memory [ 0.000000] Base memory trampoline at [ffff880000098000] 98000 size 19456 [ 0.000000] init_memory_mapping: [mem 0x00000000-0x000fffff] [ 0.000000] init_memory_mapping: [mem 0x3fe00000-0x4fffffff] [ 0.000000] init_memory_mapping: [mem 0x3c000000-0x4fdfffff] [ 0.000000] init_memory_mapping: [mem 0x00100000-0x4bffffff] [ 0.000000] kexec: crashkernel=auto resulted in zero bytes of reserved memory. [ 0.000000] Early memory node ranges [ 0.000000] PM: Registered nosave memory: [mem 0x0003e000-0x0003ffff] [ 0.000000] PM: Registered nosave memory: [mem 0x000a0000-0x000dffff] [ 0.000000] PM: Registered nosave memory: [mem 0x000e0000-0x000fffff] [ 0.000000] please try ‘cgroup_disable=memory’ option if you don’t want memory cgroups [ 0.030181] Initializing cgroup subsys memory [ 0.862358] Freeing initrd memory: 23532k freed [ 1.064599] Non-volatile memory driver v1.3 [ 1.069351] crash memory driver: version 1.1 [ 1.186673] Freeing unused kernel memory: 1430k freed [ 5.567780] [TTM] Zone kernel: Available graphics memory: 480345 kiB [root@destroyer ~]#7. Инвертирование с помощью команды grep в Linux
Допустим, если вы хотите отобразить все слова в файле, который не содержит какое-либо конкретное слово, то используйте опцию «-v». Это позволяет создать один файл с содержимым, как показано ниже:
[root@destroyer tmp]# cat test.txt Andreyex12 Andreyex454 Andreyex34343 Andreyex LinuxRoutes Linux [root@destroyer tmp]#Если мы не хотим печатать строки, содержащие слово Linux, то используйте следующую команду.
[root@destroyer tmp]# grep -v Linux test.txt Andreyex12 Andreyex454 Andreyex34343 Andreyex8. Точное совпадение слова
В соответствии с примером, приведенным в пункте 7, если мы ищем Andreyex, то он будет печатать все вхождение Andreyex как «Andreyex12», «Andreyex454», «Andreyex34343», а также «Andreyex», как показано ниже:
[root@destroyer tmp]# grep Andreyex test.txt Andreyex12 Andreyex454 Andreyex34343 Andreyex [root@destroyer tmp]#тогда, если мы хотим найти точное слово «Andreyex» вместо этого, чтобы перечислить весь вывод выше, то используйте опцию «-w», как показано ниже:
[root@destroyer tmp]# grep -w Andreyex test.txt Andreyex [root@destroyer tmp]#Количество совпадающих линий
Вы можете отобразить количество совпадающих строк, используя команду grep с -. В итоге, выполнив следующую команду, вы найдете количество строк Linuxvsem в names.txt файле:
grep -c Linuxvsem name.txt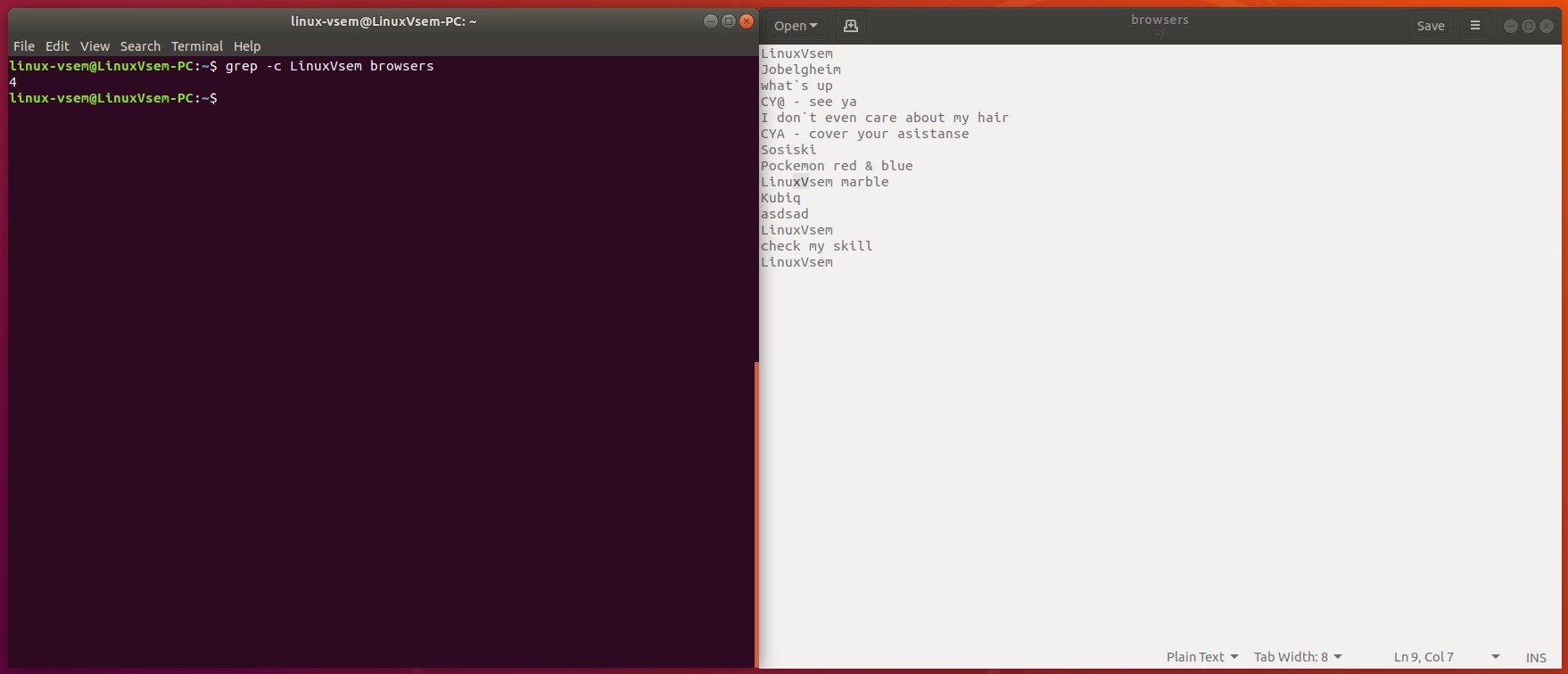
Инвертирование совпадений в команде Grep
Параметр Invert match ( -v) используется для инвертирования вывода grep. Команда отобразит строки, которые не соответствуют заданному шаблону.
Чтобы отобразить строки, которые не совпадают со строкой Linuxvsem в файле names.txt, выполните следующую команду.
grep -v Linuxvsem name.txt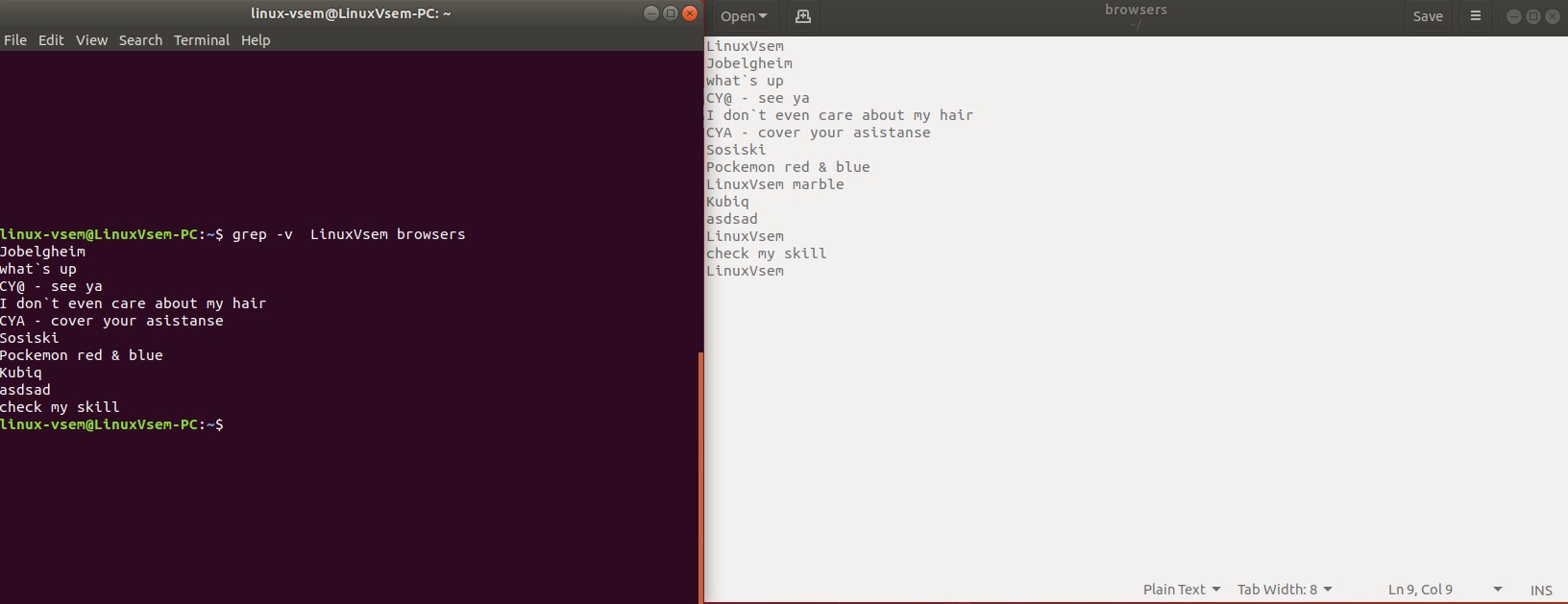
Строка поиска в стандартном выводе
Если необходимо найти строку в выводе команды — это можно сделать, комбинируя команду grep с другой командой.
Например, чтобы найти строку inet6 в выводе команды, ifconfig выполните следующую команду:
ifconfig | grep inet6
Рекурсивный поиск
Для поиска заданной строки во всех файлах внутри каталога -rиспользуется опция -recursive.
В приведенном ниже примере строка «Linuxvsem» будет найдена во всех файлах внутри каталога linux:
grep -r Linuxvsem / Documents/ linux
Используя опцию, -R вы также можете искать файлы символьных ссылок внутри каталогов:
grep -R Linuxvsem / Документы / linux
Для поиска строки во всех каталогах вы можете запустить следующую команду:
grep -r » Linuxvsem » *
Просмотр номеров строк, содержащих совпадения
Еще полезнее может быть информация о месторасположении строки с совпадением в файле. Если указать опцию –n, grep перед каждой содержащей совпадение строкой будет выводить ее номер в файле:
$ grep –-color -n “bla bla” listing.txt 18:You will find that all of bla bla are impeccably designed and meet the highest manufacturing standards available
Перед содержащей соответствие строкой выведено «18:», что соответствует 18-й строке.
Выполнение поиска без учета регистра
Допустим, фраза «string search» расположена в начале предложения или набрана в верхнем регистре. Для поиска без учета регистра можно указать опцию –i:
$ grep –-color –n -i “string search” listing.txt 18:
You will find that all of string search are impeccably designed and meet the highest manufacturing standards available anywhere.
23:
String search are manufactured using only the finest top-grain leather.
$
С опцией -i grep находит также совпадение в строке 23.
[spoiler title=”Источники”]- https://www.linux16.ru/articles/regulyarnye-vyrazheniya-grep-egrep-sed-v-linux.html
- https://linuxvsem.ru/commands/grep-linux
- https://www.hostinger.ru/rukovodstva/komanda-grep-v-linux/
- https://lumpics.ru/linux-grep-command-examples/
- https://ITProffi.ru/utilita-grep-v-os-linux/
- https://andreyex.ru/operacionnaya-sistema-linux/polnoe-rukovodstvo-komanda-grep-v-linux/










